本文最后更新于 1 分钟前,文中所描述的信息可能已发生改变。
文件分析
一、本文介绍
本文给大家带来的是YOLOv8项目的解读,之前给大家分析了YOLOv8的项目文件分析,这一篇文章给大家带来的是模型训练从我们的yaml文件定义到模型的定义部分的讲解,我们一般只知道如何去训练模型,和配置yaml文件,但是对于yaml文件是如何输入到模型里,模型如何将yaml文件解析出来的确是不知道的,本文的内容接上一篇的代码逐行解析(一) 项目目录分析,本文对于小白来说非常友好,非常推荐大家进行阅读,深度的了解模型的工作原理已经流程,下面我们从yaml文件来讲解。
本文的讲解全部在代码的对应位置进行注释介绍非常详细,以下为部分内容的截图。
二、yaml文件的定义
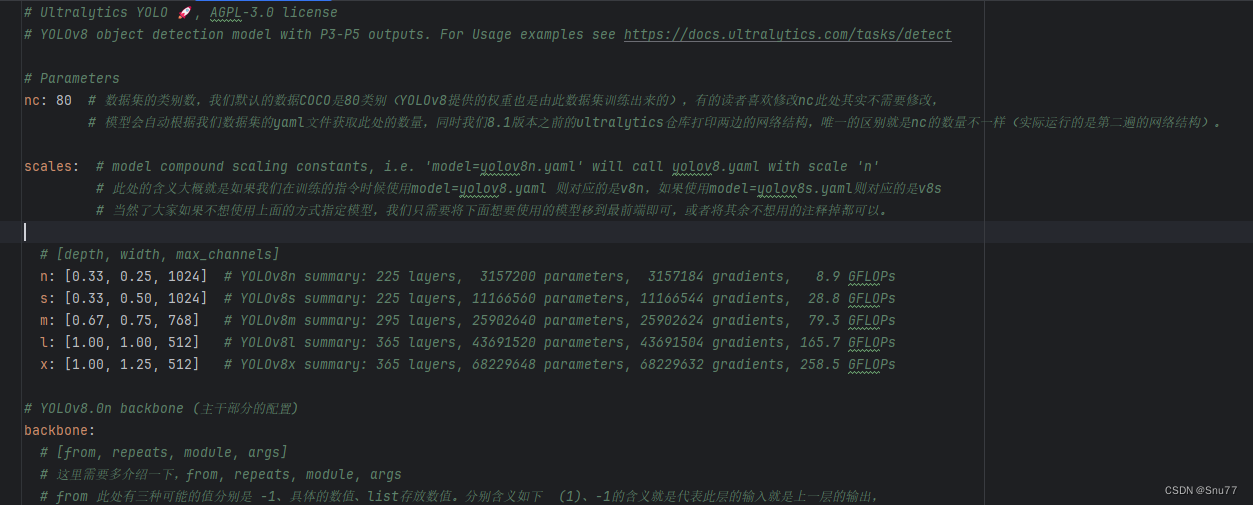
我们训练模型的第一步是需要配置yaml文件,我们的讲解第一步也从yaml文件来开始讲解,YOLOv8的yaml文件存放在我们的如下目录内’ultralytics/cfg/models/v8’,在其中我们可以定义各种模型配置的文件组合不同的模块,我们拿最基础的YOLOv8yaml文件来讲解一下。
注释部分的内容我就不介绍了,我只介绍一下其中有用的部分,我已经在代码中对应的位置注释上了解释,大家可以看这样看起来也直观一些。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # 数据集的类别数,我们默认的数据COCO是80类别(YOLOv8提供的权重也是由此数据集训练出来的),有的读者喜欢修改nc此处其实不需要修改,
# 模型会自动根据我们数据集的yaml文件获取此处的数量,同时我们8.1版本之前的ultralytics仓库打印两边的网络结构,唯一的区别就是nc的数量不一样(实际运行的是第二遍的网络结构)。
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# 此处的含义大概就是如果我们在训练的指令时候使用model=yolov8.yaml 则对应的是v8n,如果使用model=yolov8s.yaml则对应的是v8s
# 当然了大家如果不想使用上面的方式指定模型,我们只需要将下面想要使用的模型移到最前端即可,或者将其余不想用的注释掉都可以。
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone (主干部分的配置)
backbone:
# [from, repeats, module, args]
# 这里需要多介绍一下,from, repeats, module, args
# from 此处有三种可能的值分别是 -1、具体的数值、list存放数值。分别含义如下 (1)、-1的含义就是代表此层的输入就是上一层的输出,
# (2)、如果是具体的某个数字比如4那么则代表本层的输入来自于模型的第四层,
# (3)、有的层是list存放两个值也可能是多个值,则代表对应两个值的输出为本层的输入
# repeats 这个参数是为了C2f设置的其它的模块都用不到,代表着C2f当中Bottleneck重复的次数,比如当我们的模型用的是l的时候,那么repeats=3那么则代表C2f当中的Bottleneck串行3个。
# module 此处则代表模型的名称
# args 此处代表输入到对应模块的参数,此处和parse_model函数中的定义方法有关,对于C2f来说传入的参数->第一个参数是上一个模型的输出通道数,第二个参数就是args的第一个参数,然后以此类推。
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)其中的Conv和C2f的结构我就不过多解释了,网上教程已经很多了,其中详细的结构在下图中都能够看到。
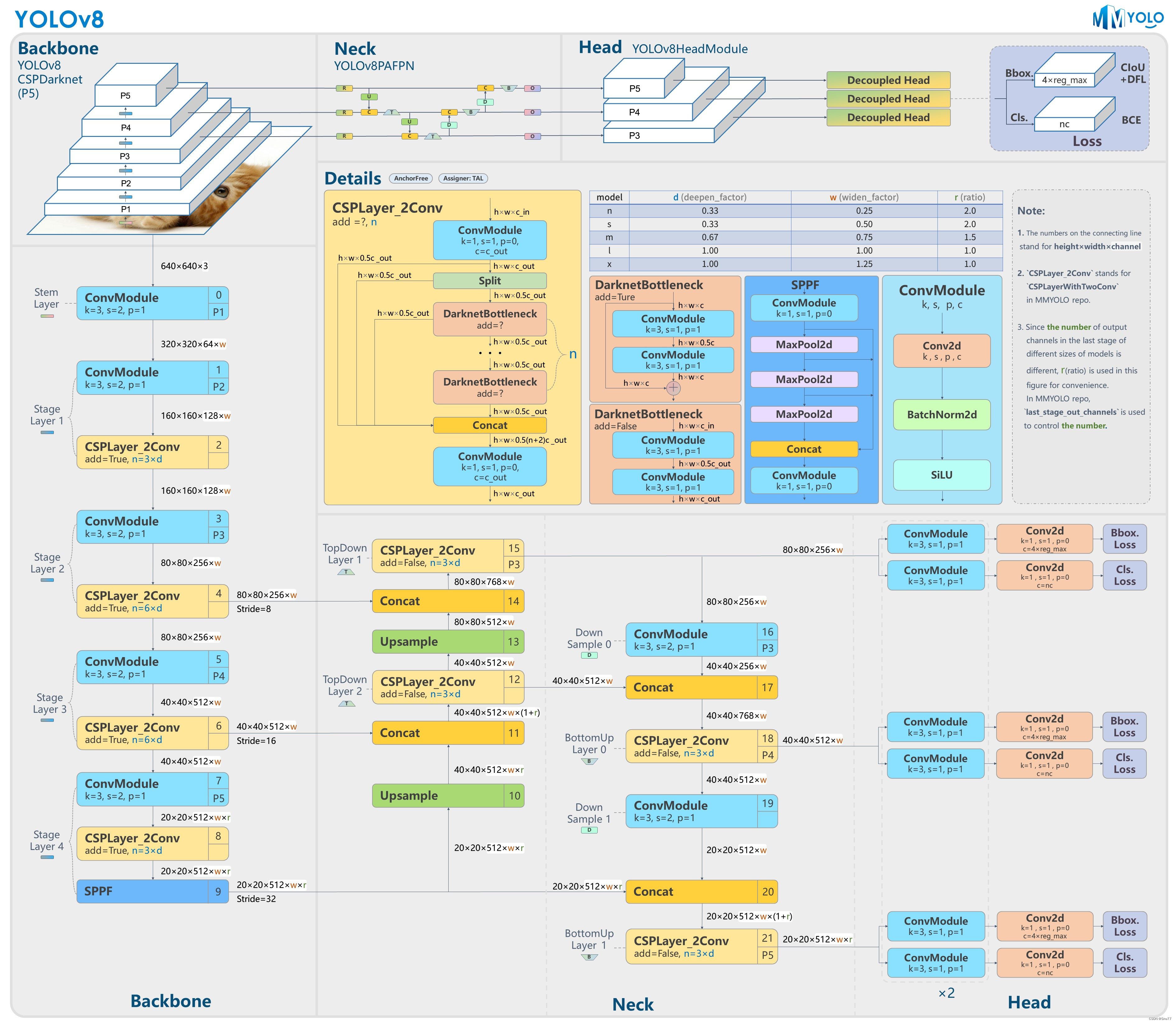
三、yaml文件的输入
上面我们解释了yaml文件中的参数含义,然后提供了一个结构图(其中能够获取到每个模块的详细结构,该结构图来源于官方)。然后我们下一步介绍当定义好了一个ymal文件其是如何传入到模型的内部的,模型的开始在哪里。
3.1 模型的定义
我们通过命令行的命令或者创建py文件运行模型之后,模型最开始的工作是模型的定义操作。模型存放于文件’ultralytics/engine/model.py’内部,首先需要通过’__init__'来定义模型的一些变量。
此处我将模型的定义部分的代码解释了一下,大家有兴趣的可以和自己的文件对比着看。
class Model(nn.Module):
import torch.nn as nn
class Model(nn.Module):
"""
一个统一所有模型API的基类。
参数:
model (str, Path): 要加载或创建的模型文件的路径。
task (Any, 可选): YOLO模型的任务类型。默认为None。
属性:
predictor (Any): 预测器对象。
model (Any): 模型对象。
trainer (Any): 训练器对象。
task (str): 模型任务类型。
ckpt (Any): 如果从*.pt文件加载的模型,则为检查点对象。
cfg (str): 如果从*.yaml文件加载的模型,则为模型配置。
ckpt_path (str): 检查点文件路径。
overrides (dict): 训练器对象的覆盖。
metrics (Any): 用于度量的数据。
方法:
__call__(source=None, stream=False, **kwargs):
预测方法的别名。
_new(cfg:str, verbose:bool=True) -> None:
初始化一个新模型,并从模型定义中推断任务类型。
_load(weights:str, task:str='') -> None:
初始化一个新模型,并从模型头中推断任务类型。
_check_is_pytorch_model() -> None:
如果模型不是PyTorch模型,则引发TypeError。
reset() -> None:
重置模型模块。
info(verbose:bool=False) -> None:
记录模型信息。
fuse() -> None:
为了更快的推断,融合模型。
predict(source=None, stream=False, **kwargs) -> List[ultralytics.engine.results.Results]:
使用YOLO模型进行预测。
返回:
list(ultralytics.engine.results.Results): 预测结果。
"""
def __init__(self, model: Union[str, Path] = "yolov8n.pt", task=None, verbose=False) -> None:
"""
Initializes the YOLO model.
Args:
model (Union[str, Path], optional): Path or name of the model to load or create. Defaults to 'yolov8n.pt'.
task (Any, optional): Task type for the YOLO model. Defaults to None.
verbose (bool, optional): Whether to enable verbose mode.
"""
"""
此处为上面的解释
初始化 YOLO 模型。
参数:
model (Union[str, Path], 可选): 要加载或创建的模型的路径或名称。默认为'yolov8n.pt'。
task (Any, 可选): YOLO 模型的任务类型。默认为 None。
verbose (bool, 可选): 是否启用详细模式。
"""
super().__init__()
"""此处就是读取我们的yaml文件的地方,callbacks.get_default_callbacks()会将我们的yaml文件进行解析然后将名称返回回来存放在self.callbacks中"""
self.callbacks = callbacks.get_default_callbacks()
""" 下面的部分就是一些模型的参数定义,我大概解释了一下,大家其实也不用太了解,一篇文章也介绍不了太多"""
self.predictor = None # 重用预测器
self.model = None # 模型对象
self.trainer = None # 训练器对象
self.ckpt = None # 如果从*.pt文件加载的检查点对象
self.cfg = None # 如果从*.yaml文件加载的模型配置
self.ckpt_path = None # 检查点文件路径
self.overrides = {} # 训练器对象的覆盖设置
self.metrics = None # 验证/训练指标
self.session = None # HUB 会话
self.task = task # 任务类型
self.model_name = model = str(model).strip() # 去除空格
# 检查是否为来自 https://hub.ultralytics.com 的 Ultralytics HUB 模型
if self.is_hub_model(model):
# 从 HUB 获取模型
checks.check_requirements("hub-sdk>0.0.2")
self.session = self._get_hub_session(model)
model = self.session.model_file
# 检查是否为 Triton 服务器模型
elif self.is_triton_model(model):
self.model = model
self.task = task
return
# 加载或创建新的 YOLO 模型
model = checks.check_model_file_from_stem(model) # 添加后缀,例如 yolov8n -> yolov8n.pt
""" 此处比较重要,如果我们没有指定模型的权重.pt那么模型会根据yaml文件创建一个新的模型,如果指定了权重那么模型这回加载pt文件中的模型"""
if Path(model).suffix in (".yaml", ".yml"):
self._new(model, task=task, verbose=verbose)
else:
self._load(model, task=task)
self.model_name = model # 返回的模型则保存在self.model_name中3.2 模型的训练
我们上面讲完了模型的定义,然后模型就会根据你指定的参数来进行调用对应的函数,比如我这里指定的是detect,和train,如下图所示,然后模型就会根据指定的参数进行对应任务的训练。
图片来源于文件’ultralytics/cfg/default.yaml’ 截图。
此处执行的是ultralytics/engine/model.py’文件中class Model(nn.Module):类别的def train(self, trainer=None, **kwargs):函数,具体的解释我已经在代码中标记了。
def train(self, trainer=None, **kwargs):
"""
在给定的数据集上训练模型。
参数:
trainer (BaseTrainer, 可选): 自定义的训练器。
**kwargs (Any): 表示训练配置的任意数量的参数。
"""
self._check_is_pytorch_model() # 检查模型是否为 PyTorch 模型
if hasattr(self.session, "model") and self.session.model.id: # Ultralytics HUB session with loaded model
if any(kwargs):
LOGGER.warning("WARNING ⚠️ 使用 HUB 训练参数,忽略本地训练参数。")
kwargs = self.session.train_args # 覆盖 kwargs
checks.check_pip_update_available() # 检查 pip 是否有更新
overrides = yaml_load(checks.check_yaml(kwargs["cfg"])) if kwargs.get("cfg") else self.overrides
custom = {"data": DEFAULT_CFG_DICT["data"] or TASK2DATA[self.task]} # 方法的默认设置
args = {**overrides, **custom, **kwargs, "mode": "train"} # 最高优先级的参数在右侧
if args.get("resume"):
args["resume"] = self.ckpt_path
# 实例化或加载训练器
""" 此处将一些参数加载到模型的内部"""
self.trainer = (trainer or self._smart_load("trainer"))(overrides=args, _callbacks=self.callbacks)
if not args.get("resume"): # 仅在不续训的时候手动设置模型
# 获取模型并设置训练器
"""
此处比较重要,为开始定义我们的对应任务的模型了比如我这里task设置的为Detect,那么此处会实例化DetectModel模型。
模型存放在ultralytics/nn/tasks.py内(就是我们修改模型时候的用到的那个task.py文件)
此处就会跳转到'ultralytics/nn/tasks.py'文化内的class DetectionModel(BaseModel):类中进行初始化和模型的定义工作
"""
self.trainer.model = self.trainer.get_model(weights=self.model if self.ckpt else None, cfg=self.model.yaml)
self.model = self.trainer.model
if SETTINGS["hub"] is True and not self.session:
# 如果开启了 HUB 并且没有 HUB 会话
try:
# 创建一个 HUB 中的模型
self.session = self._get_hub_session(self.model_name)
if self.session:
self.session.create_model(args)
# 检查模型是否创建成功
if not getattr(self.session.model, "id", None):
self.session = None
except (PermissionError, ModuleNotFoundError):
# 忽略 PermissionError 和 ModuleNotFoundError,表示 hub-sdk 未安装
pass
# 将可选的 HUB 会话附加到训练器
self.trainer.hub_session = self.session
# 进行模型训练
self.trainer.train()
# 训练结束后更新模型和配置信息
if RANK in (-1, 0):
ckpt = self.trainer.best if self.trainer.best.exists() else self.trainer.last
self.model, _ = attempt_load_one_weight(ckpt)
self.overrides = self.model.args
self.metrics = getattr(self.trainer.validator, "metrics", None) # TODO: DDP 模式下没有返回指标
return self.metrics3.3 模型的网络结构打印
第三步比较重要的就是来到了’ultralytics/nn/tasks.py’(就是我们改进模型时候的那个文件)文化内的class DetectionModel(BaseModel):类中进行初始化和模型的定义工作。
这里涉及到了模型的定义和校验工作(在模型的正式开始训练之前检测模型是否能够运行的工作!)。
class DetectionModel(BaseModel):
"""YOLOv8 目标检测模型。"""
def __init__(self, cfg="yolov8n.yaml", ch=3, nc=None, verbose=True): # model, input channels, number of classes
"""使用给定的配置和参数初始化 YOLOv8 目标检测模型。"""
super().__init__()
self.yaml = cfg if isinstance(cfg, dict) else yaml_model_load(cfg) # cfg 字典
# 定义模型
ch = self.yaml["ch"] = self.yaml.get("ch", ch) # 输入通道数
if nc and nc != self.yaml["nc"]:
LOGGER.info(f"覆盖 model.yaml nc={self.yaml['nc']} 为 nc={nc}")
self.yaml["nc"] = nc # 覆盖 YAML 中的值
""" 此处最为重要,涉及到了我们修改模型的配置的那个函数parse_model,
这里返回了我们的每一个模块的定义,也就是self.model保存了我们的ymal文件所有模块的实例化模型
self.save保存列表 | 也就是除了from部分为-1的部分比如from为4那么就将第四层的索引保存这里留着后面备用,
"""
self.model, self.save = parse_model(deepcopy(self.yaml), ch=ch, verbose=verbose) # 模型,保存列表
self.names = {i: f"{i}" for i in range(self.yaml["nc"])} # 默认名称字典
self.inplace = self.yaml.get("inplace", True)
# 构建步长
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment, Pose, Detect_AFPN4, Detect_AFPN3, Detect_ASFF, Detect_FRM, Detect_dyhead,
CLLAHead, Detect_dyhead3, Detect_DySnakeConv, Segment_DySnakeConv,
Segment_DBB, Detect_DBB, Pose_DBB, OBB, Detect_FASFF)):
s = 640 # 2x 最小步长
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, (Segment, Segment_DySnakeConv, Pose, Pose_DBB, Segment_DBB, OBB)) else self.forward(x)
try:
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # 在 CPU 上进行前向传播
except RuntimeError:
try:
self.model.to(torch.device('cuda'))
m.stride = torch.tensor([s / x.shape[-2] for x in forward(
torch.zeros(1, ch, s, s).to(torch.device('cuda')))]) # 在 CUDA 上进行前向传播
except RuntimeError as error:
raise error
self.stride = m.stride
m.bias_init() # 仅运行一次
else:
self.stride = torch.Tensor([32]) # 默认步长,例如 RTDETR
# 初始化权重和偏置
initialize_weights(self)
if verbose: # 此处为获取模型参数量和打印的地方。
self.info()
LOGGER.info("")3.4 parse_model的解析
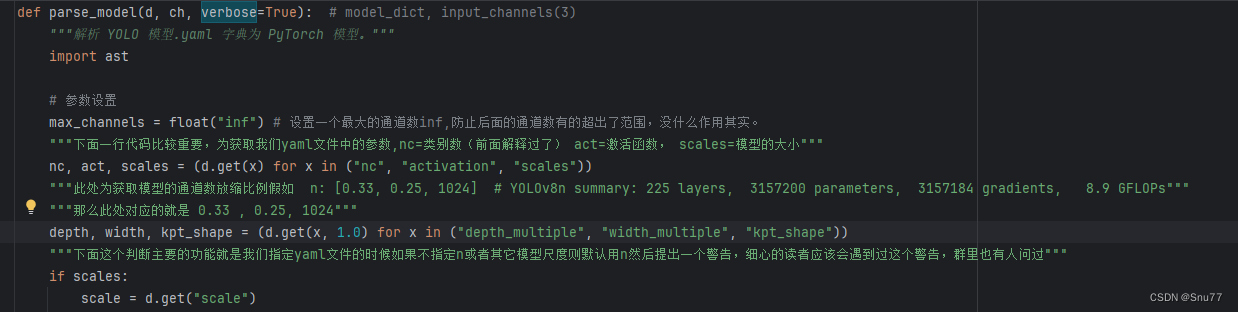
这里涉及到yaml文件中模块的定义和,通道数放缩的地方,此处大家可以仔细看看比较重要涉及到模块的改动。
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
"""解析 YOLO 模型.yaml 字典为 PyTorch 模型。"""
import ast
# 参数设置
max_channels = float("inf") # 设置一个最大的通道数inf,防止后面的通道数有的超出了范围,没什么作用其实。
"""下面一行代码比较重要,为获取我们yaml文件中的参数,nc=类别数(前面解释过了) act=激活函数, scales=模型的大小"""
nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
"""此处为获取模型的通道数放缩比例假如 n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs"""
"""那么此处对应的就是 0.33 , 0.25, 1024"""
depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
"""下面这个判断主要的功能就是我们指定yaml文件的时候如果不指定n或者其它模型尺度则默认用n然后提出一个警告,细心的读者应该会遇到过这个警告,群里也有人问过"""
if scales:
scale = d.get("scale")
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ 没有传递模型比例。假定 scale='{scale}'。")
depth, width, max_channels = scales[scale]
if act:
Conv.default_act = eval(act) # 重新定义默认激活函数,例如 Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # 打印
if verbose:
LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
ch = [ch] # 存放第一个输入的通道数,这个ch后面会存放所有层的通道数,第一层为通道数是ch=3也就是对应我们一张图片的RGB图片的三基色三个通道,分别对应红绿蓝!
layers, save, c2 = [], [], ch[-1] # 提前定义一些之后存放的容器分别为,模型层,保存列表,输出通道数
"""下面开始正式解析模型的yaml文件然后进行定义的操作用for训练便利yaml文件"""
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
m = getattr(torch.nn, m[3:]) if "nn." in m else globals()[m] # 获取模块
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
""" 此处为repeat那个参数的放缩操作,不过多解释了,最小的n是1(就是是说你yaml文件里定义的是3,然后和放缩系数相乘然后和1比那个小取那个)"""
n = n_ = max(round(n * depth), 1) if n > 1 else n
"""下面是一些具体模块的定义操作了"""
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3):
c1, c2 = ch[f], args[0]
if c2 != nc: # 如果 c2 不等于类别数(即 Classify() 输出)
""" 绝大多数情况下都不等,我们放缩通道数,也就是为什么不同大小的模型参数量不一致的地方因为参数量主要由通道数决定,GFLOPs主要有图像的宽和高决定"""
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # 嵌入通道数
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # 头部数量
"""此处需要解释一下,大家需要仔细注意此处"""
""" 这个args就是传入到我们模型的参数,C1就是上一层的或者指定层的输出的通道数,C2就是本层的输出通道数, *args[1:]就是其它的一些参数比如卷积核步长什么的"""
""" 此处和注意力机制不同的是,为什么注意力机制不在此处添加因为注意力机制不改变模型的维度,所以一般只需要指定一个输入通道数就行,
所以这也是为什么我们在后面定义注意力需要额外添加代码的原因有兴趣的读者可以对比一下"""
args = [c1, c2, *args[1:]]
""" 此处就是涉及的上面求出的实际的n然后插入的参数列表中去,然后准备在最下面进行传参"""
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # 重复次数
n = 1
"""这些都是一些具体的模块定义的方法,不多解释了"""
elif m is AIFI:
args = [ch[f], *args]
elif m in (HGStem, HGBlock):
c1, cm, c2 = ch[f], args[0], args[1]
args = [c1, cm, c2, *args[2:]]
if m is HGBlock:
args.insert(4, n) # 重复次数
n = 1
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in (Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn):
args.append([ch[x] for x in f])
if m is Segment:
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
elif m is RTDETRDecoder: # 特殊情况,channels 参数必须在索引 1 中传递
args.insert(1, [ch[x] for x in f])
else:
c2 = ch[f]
"""此处就是模型的正式定义和传参的操作"""
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # 模块
t = str(m)[8:-2].replace("__main__.", "") # 模块类型
m.np = sum(x.numel() for x in m_.parameters()) # 参数数量
m_.i, m_.f, m_.type = i, f, t # 附加索引,'from' 索引,类型
if verbose:
LOGGER.info(f"{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}") # 打印
"""此处就是保存一些索引通道数涉及到from的部分,此处文字很难解释的清楚有兴趣可以自己debug看一下就明白了"""
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # 添加到保存列表
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)四、模型的结构打印
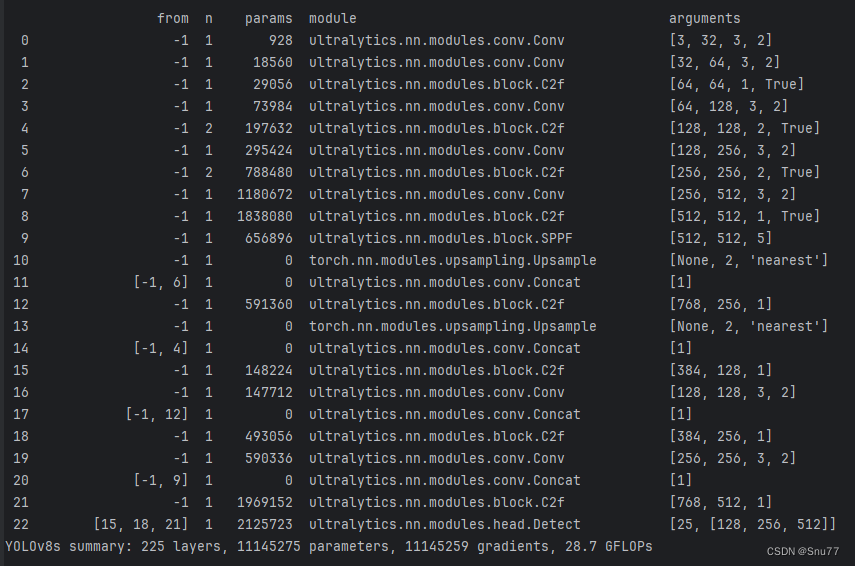
经过上面的分析之后,我们就会打印了模型的结构,图片如下所示,然后到此本篇文章的分析就到这里了,剩下的下一篇文章讲解。
(需要注意的是上面的讲解整体是按照顺序但是是以递归的形式介绍,比如3.2是3.1当中的某一行代码的功能而不是结束之后才允许的3.2,而是3.1运行的过程中运行了3.2。)